Star-Tree Index in Apache Pinot - Part 3 - Understanding the Impact in Real Customer Scenarios
By: Sandeep Dabade, Kulbir Nijjer
July 12th, 2023 • 8 min read
In part 1 of this blog series, we looked at how a star-tree index brought down standalone query latency on a sizable dataset of ~633M records from 1,513ms to 4ms! — nearly 380x faster.
In part 2 of this blog series, we imitated a real production scenario by firing hundreds of concurrent queries using JMeter and showcased how using a star-tree index helped achieve a >95% drop in p90th / p95th / p99th latencies and 126x increase in Throughput.
In this part, we will cover some real customer stories that have seen 95% to 99% improvement in query performance using Star-Tree Index.
AdTech Use Case
This was for a leading AdTech platform and a somewhat typical use case; users of the platform (advertisers, publishers, and influencers) wanted to see fresh metrics on how their activities (such as online content, ad, and email campaigns) were performing in real-time so they could tweak things as needed. The application team wanted to provide a rich analytical interface to these users so that not only can they see the current performance but also do custom slicing and dicing of data over a period of time. For example, compare their current campaign performance to one they ran two weeks back, do cohort analysis, and so on.
Why was the existing system not working?
Their existing tech stack was a mix of OSS and custom-built in-house code, which was both operationally difficult to manage and costly to maintain. Yet more importantly, it wasn’t able to meet the basic throughput and latency requirements required by the platform to sustain user growth as well as provide richer analytic capabilities in the product.
The Problem and Challenges?
When the StarTree Sales Engineering team was engaged, the requirements were very clear:
- Throughput: Support 50+ QPS during POC and 200+ for production)
- Latency: P95th latency of 2s, including query that needed aggregation of ~ 2 billion rows
- Scalability: Ability to scale efficiently with future growth in QPS in a non-linear manner
The biggest challenge was the size of data — 20+ TB and growing — and on top of that, a complex aggregation query driving the summary view for users so they can drill further in to get more details.
This particular query needed to aggregate close to 2 Billion records at read time and then would be fired for every active user interacting with the platform (so high concurrent QPS). In this case, despite applying all relevant indexes available in their existing system, out-of-the-box query performance was still in the 6-8 seconds range, which is expected given that bulk of the work for the query is happening in the aggregation phase and not during the filtering phase (indexing helps with this).
In other OLAP systems they explored, the only option available to handle this use case was doing ingestion time rollups. In other words, changing the data to higher granularity. However, this obviously means losing access to raw data and also potentially re-bootstrapping if new use cases come down the road that need raw data access.
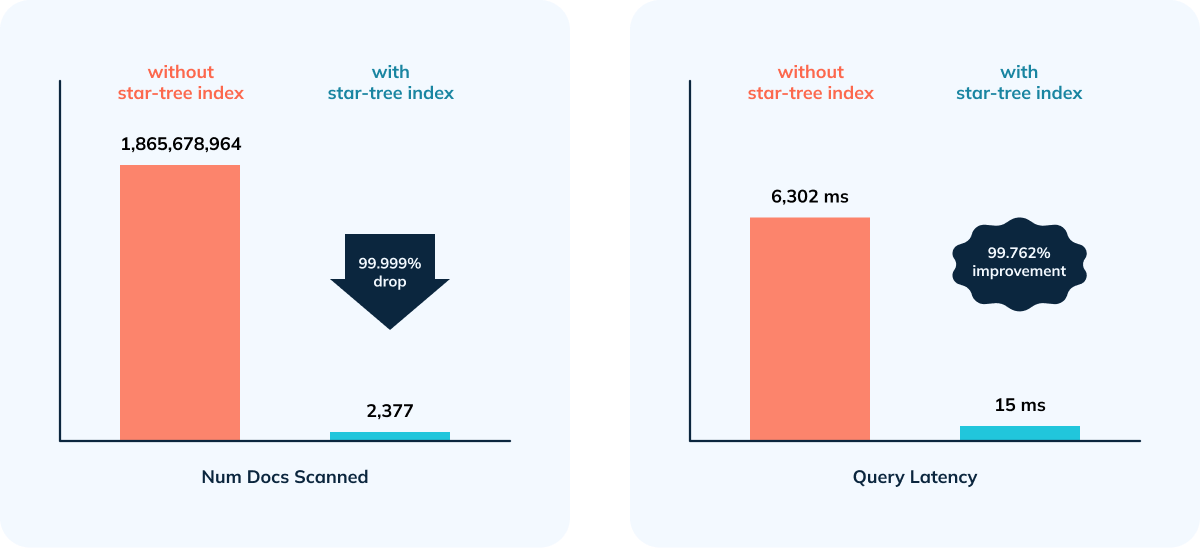
This is exactly the type of scenario that the Star-Tree Index, unique to Apache Pinot, is designed to address - handle large aggregation queries at scale that need sub-second performance. The best part is you can apply it anytime without any need to reprocess the data or plan any system downtime. (Segment reload to apply table config changes run as a background task in Apache Pinot.) In this specific case, the same query latencies with the star-tree index applied went down to 15 ms. This implicitly meant that with the same infrastructure footprint, StarTree was able to support ~70 QPS (Queries Per Second) vs < 1 QPS for this most complex query; while still keeping the raw data intact.
Data Size and Infra Footprint for the Pilot:
- Total # of records: ~2 Trillion
- Data Size: ~20 TB
- Capacity: 72 vCPUs across 9 Pinot servers (8 vCPU, 64GB per node).
Impact Summary:
- 99.76% reduction in latency vs. no Star-Tree Index (6.3 seconds to 15 ms)
- 99.99999% reduction in amount of data scanned/aggregated per query (> 1.8B docs to < 2,400)
CyberSecurity Use Case:
A cybersecurity company that provides their customers with a real-time threat detection platform with AI, allowing them to analyze network flow logs in real-time with a sophisticated reporting/analytical UI. The initial landing page inside the customer portal is a summary view of everything the platform was monitoring in the user's environment and then provides the capability to drill down into specifics of each. For example, filter requests by a specific application or IP Address.
Why was the existing system not working?
Their existing tech stack was a mix of Athena/Presto, which couldn’t meet the throughput and latency requirements with growing data volume across their customers. Additionally, operational overhead around managing some of these systems in-house led to increased cost.
The Problem and Challenges?
Some of the key requirements that StarTree Cloud cluster had to meet:
- Throughput: Up to 200 QPS (200 projected by end of year)
- Latency: < 1 second P99
- High ingestion rate: 300k events/sec
- ROI: Provide better cost efficiencies
Similar to Use case #1, the customer wanted to retain data at the lowest granularity (so no ingestion roll-ups), and given the time column granularity similar challenge with running the complex aggregation query to power off the summary view. Additionally, the requirement to get double-digit throughput(QPS) for the POC with the most efficient compute footprint made it quite challenging.
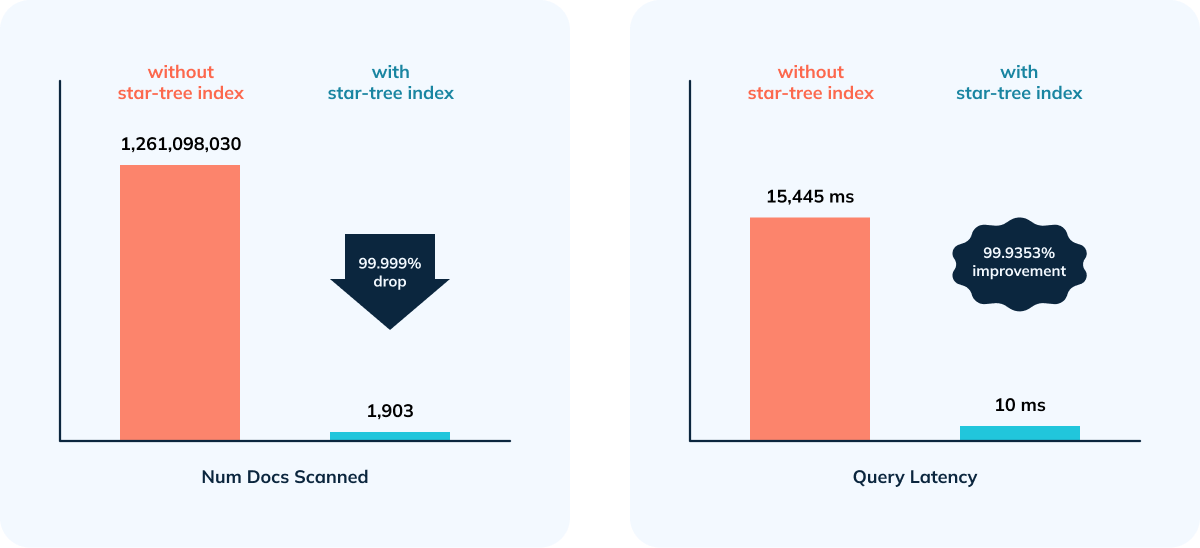
Given the overhead while doing complex aggregations, efficient filtering (indexes) wasn’t enough - in this case, with 3 * 4-core/32GB nodes query took more than 15 seconds. We immediately switched the table config to add star-tree index to the table config and do a segment reload, and the results were phenomenal — query latency was reduced to 10ms.
Data Size and Infra Footprint for the Pilot:
- Total # of records: ~8 Billion
- Data Size: 500+ GB
- Capacity: 12 vCPUs across 3 Pinot servers (4-core/32GB)
Impact Summary:
- 99.94% reduction in query latency (achieving 100 QPS for the same query with no extra hardware)
- 99.9998% reduction in data scanned/aggregated per query
- Happy Customer 😃
Multiplayer Game Leaderboard Use Case
A global leader in the interactive entertainment field has an A/B Testing / Experimentation use case that tracks players’ activities to measure the player engagement on the new features being rolled out.
The Problem and Challenges?
Some of the key requirements that StarTree Cloud cluster had to meet:
- Throughput: = 200 QPS
- Latencies: < 1 second P99
- Ingestion rate: 50K events/sec
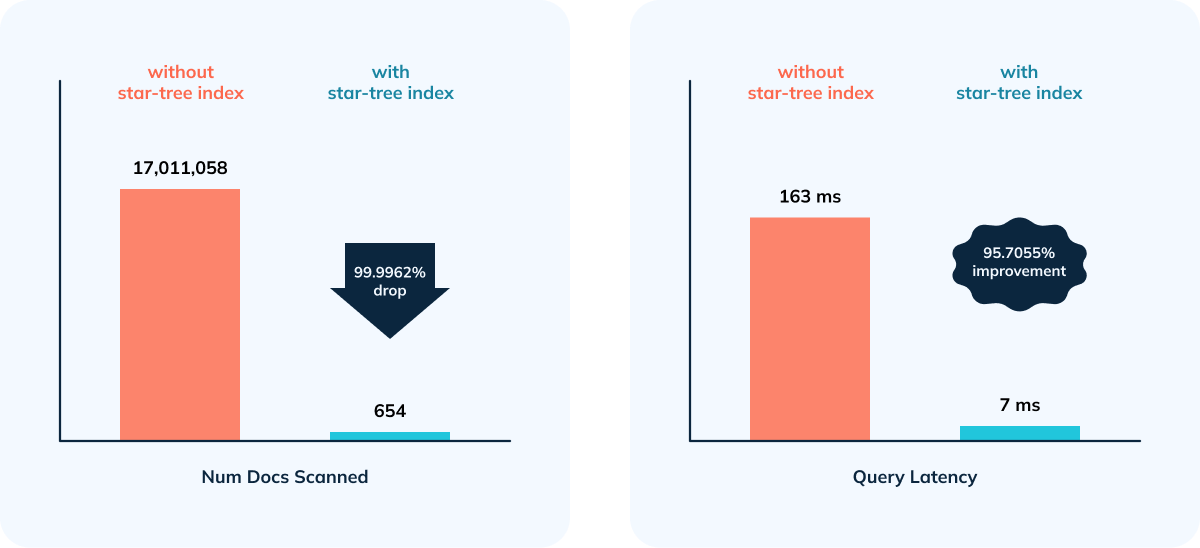
Given the overhead while doing complex aggregations, efficient filtering (indexes) wasn’t enough - in this case, with 1 * 4-core/32GB nodes query took 163 milliseconds. After switching to a star-tree index, the query latency was reduced to 7ms (a reduction of 95.7%).
Data Size and Infra Footprint for the Pilot:
- Total # of records: ~34 Million
- Data Size: 500+ GB
- Capacity: 4 vCPUs - 1 Pinot server (4-cores / 32 GB)
Impact Summary:
- 95.70% improvement in query performance as a result of 99.9962% reduction in number of documents and entries scanned.
Quick Recap: Star-Tree Index Performance Improvements
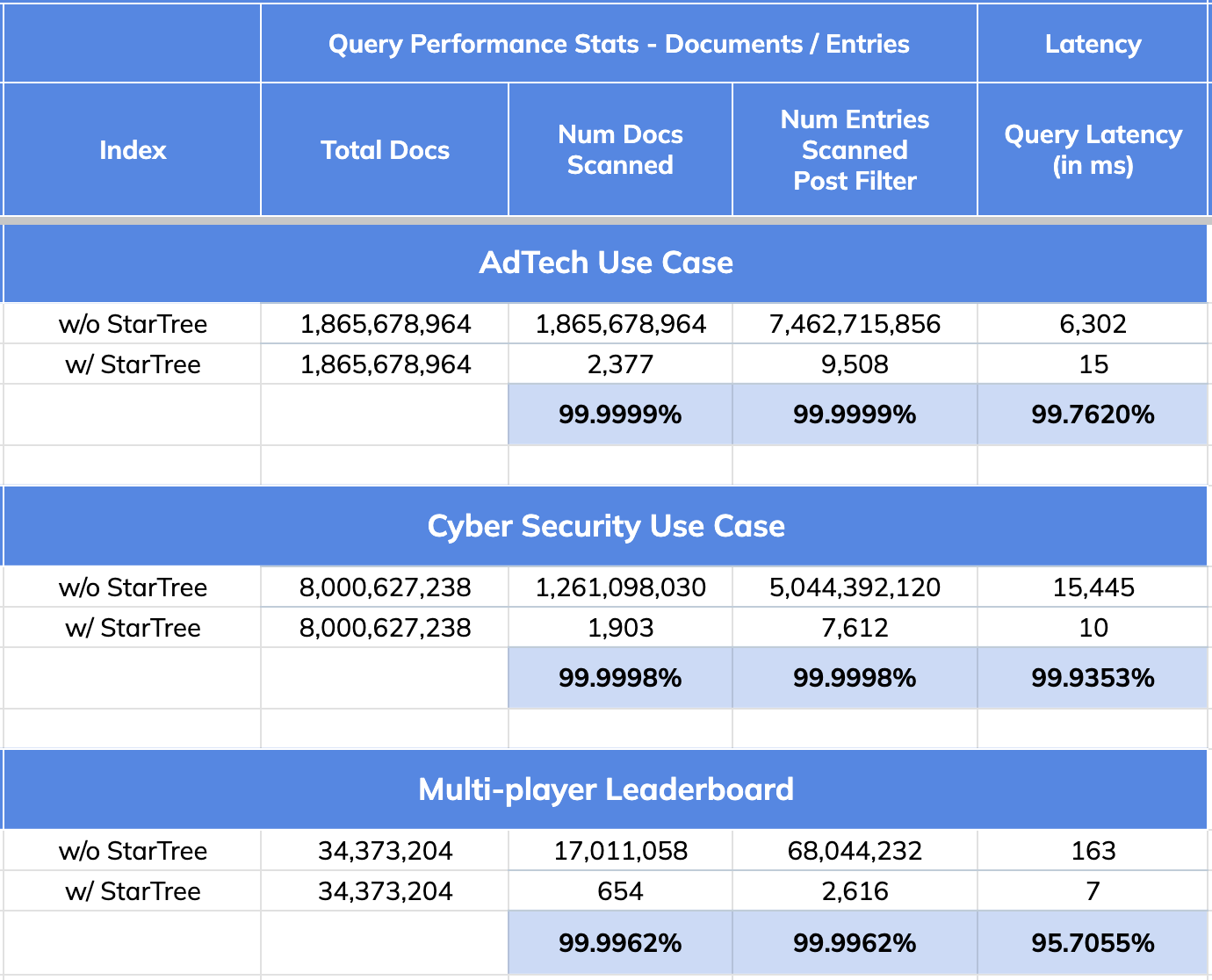
- 99.99% reduction in data scanned/aggregated per query
- 95 to 99% improvement in query performance
Disk IO is the most expensive operation in query processing. The star-tree index reduces Disk IO significantly. Instead of scanning raw documents from the disk and computing aggregates on the fly, star-tree index scans pre-aggregated documents for the combination of dimensions specified in the query from the disk.
In part 1 of the series, we saw that the star-tree index reduced the disk reads by 99.999% from 584 Million entries (in case of an inverted index) to 2,045. Query latency came down 99.67% from 1,513 ms to 4 ms! This, in itself, was a HUGE benefit.
In addition to the drastic improvement in query latency, the memory and CPU usage decreased significantly, freeing up resources for taking up more concurrent workloads. The cumulative effect was the 126 x increase in QPS on this small 4 vCPU Pinot Server, as we saw in part 2 blog of this series.
And finally, in this part 3 of the blog series, we covered three real production use cases that have seen 95% to 99% improvement in query performance using Star-Tree Index.
Intrigued by What You’ve Read?
The next step is to load your data into an open-source Apache Pinot cluster or, if you prefer, a fully-managed database-as-a-service (DBaaS). Sign up today for a StarTree Cloud account, free for 30 days. If you have more questions, sign up for the StarTree Community Slack.
